

This is the second installment in a series. Read part 1 here.
The ultimate root of the stupidity of AI systems, I argue, lies in their strictly algorithmic character. AI as presently understood is based on digital processing systems that carry out binary-numerical operations in a step-by-step fashion according to fixed sets of algorithms, starting from an array of numerical inputs.
Some may object to this characterization, pointing out that AI systems can constantly change their own “rules” – reprogramming themselves, so to speak. That is true; but the self-reprogramming must follow some algorithm.
The same applies to the processes by which the system reacts to various inputs. Ultimately each AI system is governed by a set of rules and procedures that are embodied in the design of the system, and that remain unchanged during its operation as long as the system remains intact.
Alan Turing, one of the great pioneers of artificial intelligence, succeeded in giving a precise definition for the general notion of “algorithm” or “mechanical procedure,” which subsumes all AI systems that could possibly be realized on the basis of digital hardware. Turing demonstrated that any such system is mathematically equivalent to an abstract entity now known as a “Turing machine.”
Moreover, there is a single, universal Turing machine that can simulate any other one, when the latter’s design is input in suitably coded form. On this basis one can investigate the theoretical possibilities and limitations of AI systems by mathematical methods (speed and other physical aspects being left out of consideration).

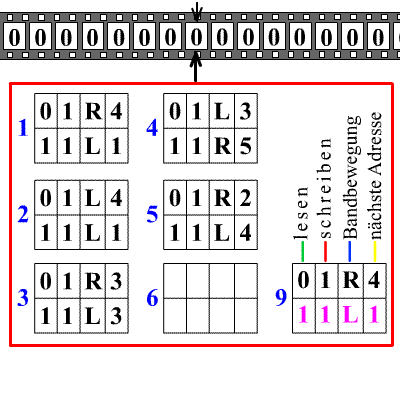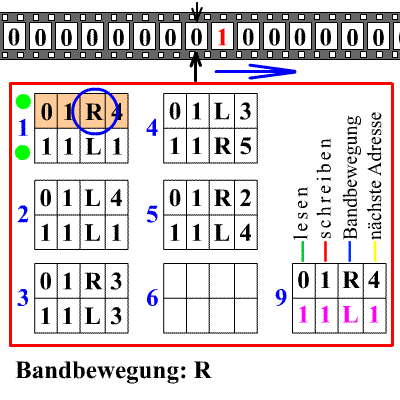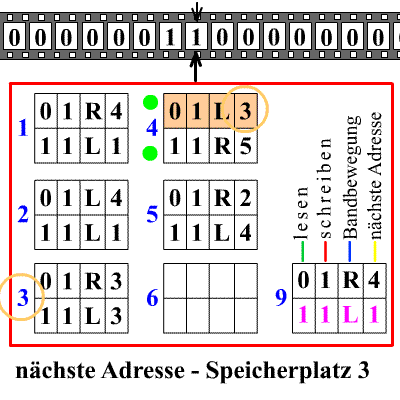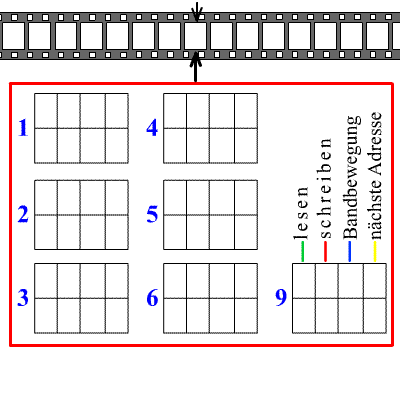
The diagram shows an endless tape with squares in which either zero or one is written. The machine has a head that can read, erase or print a zero or one, and move the tape one step to the right or left. The numbered rectangles below contain the rules (program) of the machine.
Rule 1 says, for example: if you read a zero, then erase it and print a one, move the tape one space to the right, and go to rule 4; but if you read a one, then leave the one unchanged, move the tape one space to the left, and apply rule 1 again. The machine starts at rule 1 with some sequence of zeros and ones written on the tape. There can also be a rule that tells the machine to stop.
You can link to a (rather slow) animation, showing how a Turing machine works.
{kind=link}
No matter how sophisticated an AI system might be, no matter how we might combine AI systems in various ways in interacting parallel and self-modifying hierarchical architectures, what we end up with always boils down to a Turing machine operating under a fixed set of governing rules.
Stupidity is built into AI systems, both at the lowest and the highest levels.
On the micro level we have the billions of individual switching elements on the IC chips, each of which carries out its on-off transitions in a 100% deterministic, rigidly mechanical fashion. They are 100% stupid. That is what they were built to do. They hardly resemble the living cells – neurons and glial cells, embedded in the interstitial system of the brain – that constitute the substrate for human mental processes.
At the macro level the behavior of an AI system is subservient to its governing rules. It has no way to change them from the inside. It interprets and reacts to all events accordingly and will continue to do so, even when they lead to disaster.
Thus, all AI systems based on digital hardware are inherently stupid, even when they manifest intelligent behavior, according to the first two of my four stupidity criteria as laid out in part 1 of this series. Here are those two again, to remind you:
S 1. Continued adherence to existing procedures, habits, modes of thinking and behavior, combined with an inability to recognize clear signs that these are inappropriate or even disastrous in the given concrete case. Rigid adherence to past experience and rote learning in the face of situations that call for fresh thinking. One could speak of blindly “algorithmic” behavior in the broadest sense.
S 2. Inability to “think out of the box,” to look at the bigger picture, to mentally jump out of the process in which one is engaged and pose overreaching questions such as, “What am I really doing?” and “Does it make sense?” and “What is really going on here?”
Next let’s examine a few examples for how the stupidity of AI systems manifests itself in their practical performance.
So-called deep learning systems play a dominant role in applications of AI today. The basic idea may be known to many readers, but I will briefly summarize it here.
Deep learning is based on the use of multilayered artificial neural networks. The networks are composed of layers of electrically interconnected nodes (“artificial neurons”) each of which receives inputs from nodes in the preceding layer and computes an output which goes to nodes in the following layer. The inputs to each node from other nodes are assigned relative weights, which are adjusted in the course of a “learning” process.
The first layer of nodes (the layer at the left in the diagram) receives inputs from the outside: for example, pixels of an image to be identified. The idea is, by adjusting the relevant weights, to get the nodes in each layer to respond to relevant patterns in the data from the preceding layer, so that the nodes in the final layer will give us the desired answer.
For example, we might want one of those final nodes to be activated if the image is a circle; another node, if the image is a square.
Using an exceedingly ingenious algorithm one can arrange for such a network to gradually adjust its internal parameters by itself, when presented with large number of pairs of inputs and right answers (in this example, correctly identified images), in such a way that it gives better and better answers for arbitrary inputs – at least in a statistical sense.
One might describe it as a highly sophisticated method of curve-fitting.

The deep learning approach has achieved astonishing successes. But there are also problems.
Since the optimization process is statistical in nature, it tends to give the right answers only for inputs similar to those that occurred frequently in the sets it was trained upon. For rarely-encountered inputs the results can be wildly erroneous. This so-called Black Swan phenomenon presents a major challenge to the development of self-driving vehicles, which can be faced with a great variety of unusual situations.
Equally serious is the black box problem: Deep learning networks, such as those used for image identification, have 10 or more millions of internal parameters. The values of these millions of parameters came out of a training process involving huge amounts of data.
The network has thereby become a “black box”: the input-output function of the network is mathematically so complicated that we have no way to predict or explain the system’s behavior in general.
Visual object identification, which is being employed everywhere on a vast scale, provides a case in point.
Despite constant improvements, these systems continued to be plagued by cases of wildly false identification of objects, of the sort humans would practically never make. Moreover, such errors can be provoked deliberately by so-called adversarial examples, which have become a new field of AI research.
Here (courtesy of Dan Hendrycks) are some errors in image recognition by the AI image recognition system ResNet-50 – a deep-learning neural network with 50 layers deep-trained on more than a million images.
“banana”

“school bus”

Here’s another adversarial example from the MIT Computer Science and Artificial Intelligence LAB in which a tiny perturbation of the image causes an AI image recognition system to produce a wildly erroneous interpretation.

In a typical adversary example, the image is only very slightly modified in a manner that is barely noticeable to a human viewer – but causes the AI system to produce a totally different answer.
The phenomenon of adversarial examples demonstrates that what these systems have “learned” to do differs fundamentally from how human beings recognize objects. In many cases, the systems detect a kind of texture in the image – rather than the form (Gestalt), which a human being perceives. Analogous adversarial examples can be produced for voice recognition systems.
Quite generally, what is called “learning” in existing artificial intelligence systems has little or nothing to do with the way human beings actually learn. At best one might find analogies with mindless mechanical memorization, or Skinnerian techniques of behavioral modification to which no intelligent person would submit.
Adversarial examples have become a very serious source of concern, not least of all in military (for example, target identification systems) and security uses of AI. See for example “How Adversarial Attacks Could Destabilize Military AI Systems” and “Military artificial intelligence can be easily and dangerously fooled.”
Translating without understanding
A second example is machine translation. Here, the deep learning approach has achieved extraordinary successes, in no small part thanks to its gigantic database and constant improvements. But the stupidity problem remains.
Google Translate is a good example. Google Translate operates with a vast, constantly growing database of hundreds of millions of documents and text passages with paired human-produced translations.
Among other things Google Translate utilizes the multilingual data base of the United Nations, which includes over 1.5 million aligned document pairs in the six official UN languages, and the multilingual documents base of the European Commission. Translations of phrases are generated, correlated with human-translated phrases, and statistically optimized to yield the “best” translation.
Needless to say, the Google Translate procedure involves nothing but manipulations with series of zeros and ones from its input and its database. Theoretically if a person were to live long enough – thousands of years, probably – and have sufficient patience to carry out the calculational procedures, then that person could translate texts (in digitally coded form) from Swahili into Tibetan without knowing a word of either language.
Thus, what Google Translate does is basically a (more or less) successful form of cheating: translating texts without understanding them. Lack of ability to understand is a form of stupidity (S 4).
The stupidity of Deep Learning-based machine translation often produces hilarious results. I have amused myself by feeding Chinese texts containing 成语 (chengyu) – traditional, mostly four-character idiomatic expressions – into various online translation services.
For example, the chengyu 马齿徒增 (mǎchǐtúzēng), literally “horse teeth, uselessly, grow”, could be translated – leaving behind the humor, irony and rhythm – as: “to get older without accomplishing much.” Embedded in a suitable phrase, this chengyu can cause machine translators to go wild:
平心思量,一年来马齿徒增而事业无成,也只能忍气吞声当牛做马了。
Google translator: “If you think about it for a year, your teeth will increase and your career will fail.”
As often happens, the machine translator output can be unstable. If you input the phrase more than once, you may get different translations.
Google translator (a second time): “Thoughtfully, over the past year there has been an increase in the number of teeth and no success in their careers.”
Baidu translator: “I think that in the past year, the number of horses has increased in vain and their career has not been successful. I can only bear to be an ox and a horse.”
Such examples make it obvious that the AI translation systems, at least of the presently existing sort, have no access to meaning per se. They are 100% stupid in that sense (S 4).
Next is Part 3: Curve-fitting common sense
Jonathan Tennenbaum received his PhD in mathematics from the University of California in 1973 at age 22. Also a physicist, linguist and pianist, he’s a former editor of FUSION magazine. He lives in Berlin and travels frequently to Asia and elsewhere, consulting on economics, science and technology.
